When you enter a URL and hit enter, your computer reaches out to a server someplace in the world to access a website. Sometimes a site is stored on a few servers for redundancy or load balancing, but the model is functionally the same. BitTorrent, the company behind the popular file sharing protocol, is looking to change the way websites are hosted by keeping the data not on a centralized server, but on the home computers of users. These sites would be split up into pieces just like a file shared via a torrent. BitTorrent calls this system Project Maelstrom, and it’s getting very close to reality. Project Maelstrom is built on a modified version of Chromium, the open source project that backs Google’s Chrome browser. If we extend the file sharing analogy to Project Maelstrom, the modified browser is basically your torrent client. You enter a web address, and the browser connects to a “swarm” of users already accessing the site who have pieces of it ready to send over. These bits are assembled into the final product and displayed normally. If it works as intended, you won’t notice a difference in the functionality of these sites. The torrent browser is going to be able to access regular web pages via the internet, but it’s mainly for these so-called torrent web pages. One of the main advantages here will be scalability that surpasses anything we have today on traditional server infrastructure. When a site gets hit by a lot of traffic, a server has to devote more and more bandwidth to serving content, which can easily saturate the pipes. In the case of a distributed denial of service attack (DDoS), a website can be knocked offline for hours or days. A torrent web page should actually become more reliable as it is accessed more. More seeds means more speed and accessibility. One notable drawback to Project Maelstrom would be the relative difficulty in keeping very new or unpopular sites online. When a new torrent web page is created, there is only one source for the data, probably with nowhere near the power of a dedicated web server. So the creator is the first seed, the next person to visit is the second seed, but the third person then has two sources to download from, then becoming the third seed. It’s just like a torrent — it can get stupid-fast when there are enough seeds. The decentralized nature of Project Maelstrom would also make it nearly impossible to take down a website as long as users kept seeding it. Seems like a perfect match for The Pirate Bay, right? This platform would present ethical issues, of course. What if a legitimately terrible or illegal site were hosted in Maelstrom? There might not be any way to take it down. This is something law enforcement already deals with on Tor, but Project Maelstrom has the potential to be much faster and easier to use. Still, BitTorrent thinks content providers will get on board with Maelstrom as a way to reduce costs. For example, if Netflix can detect when a user is connecting through a Maelstrom-enabled browser, it could save money by serving video content through a swarm of multiple users, rather than pushing separate streams out to everyone individually. It would be like a content delivery network on steroids. BitTorrent is going to find out if Maelstrom will be used for good or evil soon. A consumer version is expected this year. Source: http://www.extremetech.com/internet/198578-bittorrents-project-maelstrom-will-host-websites-in-torrents
View article:
BitTorrent’s Project Maelstrom will host websites in torrents
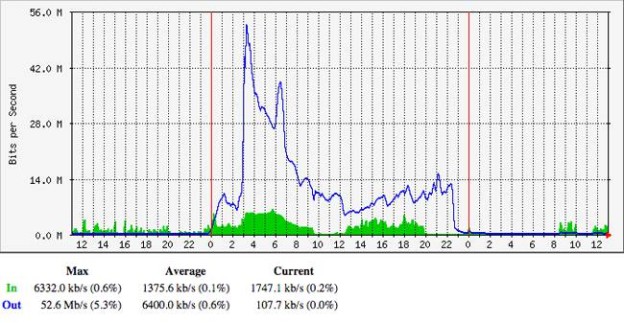
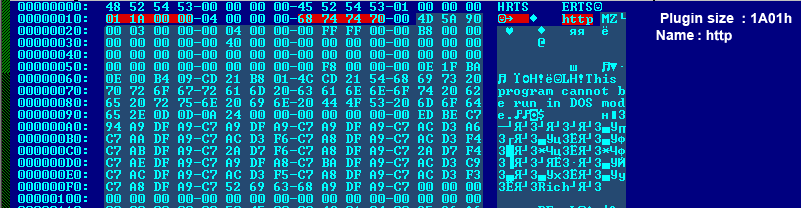
 An upgrade to China’s Great Firewall is having knock-on effects all over the internet, with seemingly random sites experiencing massive traffic spikes. One site owner in North Carolina, Craig Hockenberry, has written up how, after he looked into why his mail server was down, he found 52Mbps of search traffic piling into his system: 13,000 requests per second, or roughly a third of Google’s search traffic. The post goes into some detail over howHockenberry managed to deal with the firehose-blast of requests, all of it coming from China and much of it trying to find Bittorrents or reach Facebook. Short version: he blocked all of China’s IP blocks. Hockenberry is not the only one dealing with a sudden flood of requests, though. There are numerous reports of sysadmins finding that their IP address has appeared in front of the headlights of the Chinese government’s censorship juggernaut, causing them to fall over and forcing them to introduce blocking measures to get back online. After a number of different theories about what was happening, including focussed DDoS attacks and “foreign hackers” – that suggestion courtesy of the Chinese government itself – the overall conclusion of the technical community is that bugs have been introduced into China’s firewall. Particularly, something seems to have gone wrong in how it uses DNS cache poisoning to redirect users away from sites the government doesn’t want them to see. Poison China uses a weak spot of the DNS system to intercept requests coming into and going out of the country. If it spots something it doesn’t like – such as a request for “facebook.com” or “twitter.com” – it redirects that request to a different IP address. For a long while, China simply sent these requests into the ether – i.e. to IP addresses that don’t exist, which has the effect of causing the requests to time out. However, possibly in order to analyze the traffic more, the country has started sending requests to IP addresses used by real servers. Unfortunately, it seems that there have been some configuration mishaps and the wrong IP addresses have been entered. When one wrong number means that a server on the other side of the world suddenly gets hits with the full stream of millions of Chinese users requesting information, well then … that server falls over. The situation has had a broader impact within China. Tens of millions of users weren’t able to access the Web while the government scrambled to fix the problem. According to one Chinese anti-virus vendor, Qihoo 360, two-thirds of Chinese websites were caught up in the mess. China’s DNS infrastructure experts started pointing the finger at unknown assailants outside its system. “The industry needs to give more attention to prevent stronger DNS-related attacks,” said Li Xiaodong, executive director of China’s Internet Network Information Center (CNNIC). Your own medicine The reality, however, is that China has seen the downside to its efforts to reconfigure the basic underpinnings of the domain name system to meet political ends. The network is designed to be widely distributed and route around anything that prevents effective communication. By setting itself up as a bottleneck – and an increasingly huge bottleneck as more and more Chinese users get online – the Chinese government is making itself a single point of failure. The slightest error in its configurations will blast traffic in uncertain directions as well as cut off its own users from the internet. For years, experts have been warning about the “balkanization” of the internet, where governments impose greater and greater constraints within their borders and end up effectively breaking up the global internet. What has not been covered in much detail is the downside to the countries themselves if they try to control their users’ requests, yet make mistakes. Source: http://www.theregister.co.uk/2015/01/26/great_firewall_of_china_ddos_bug/
An upgrade to China’s Great Firewall is having knock-on effects all over the internet, with seemingly random sites experiencing massive traffic spikes. One site owner in North Carolina, Craig Hockenberry, has written up how, after he looked into why his mail server was down, he found 52Mbps of search traffic piling into his system: 13,000 requests per second, or roughly a third of Google’s search traffic. The post goes into some detail over howHockenberry managed to deal with the firehose-blast of requests, all of it coming from China and much of it trying to find Bittorrents or reach Facebook. Short version: he blocked all of China’s IP blocks. Hockenberry is not the only one dealing with a sudden flood of requests, though. There are numerous reports of sysadmins finding that their IP address has appeared in front of the headlights of the Chinese government’s censorship juggernaut, causing them to fall over and forcing them to introduce blocking measures to get back online. After a number of different theories about what was happening, including focussed DDoS attacks and “foreign hackers” – that suggestion courtesy of the Chinese government itself – the overall conclusion of the technical community is that bugs have been introduced into China’s firewall. Particularly, something seems to have gone wrong in how it uses DNS cache poisoning to redirect users away from sites the government doesn’t want them to see. Poison China uses a weak spot of the DNS system to intercept requests coming into and going out of the country. If it spots something it doesn’t like – such as a request for “facebook.com” or “twitter.com” – it redirects that request to a different IP address. For a long while, China simply sent these requests into the ether – i.e. to IP addresses that don’t exist, which has the effect of causing the requests to time out. However, possibly in order to analyze the traffic more, the country has started sending requests to IP addresses used by real servers. Unfortunately, it seems that there have been some configuration mishaps and the wrong IP addresses have been entered. When one wrong number means that a server on the other side of the world suddenly gets hits with the full stream of millions of Chinese users requesting information, well then … that server falls over. The situation has had a broader impact within China. Tens of millions of users weren’t able to access the Web while the government scrambled to fix the problem. According to one Chinese anti-virus vendor, Qihoo 360, two-thirds of Chinese websites were caught up in the mess. China’s DNS infrastructure experts started pointing the finger at unknown assailants outside its system. “The industry needs to give more attention to prevent stronger DNS-related attacks,” said Li Xiaodong, executive director of China’s Internet Network Information Center (CNNIC). Your own medicine The reality, however, is that China has seen the downside to its efforts to reconfigure the basic underpinnings of the domain name system to meet political ends. The network is designed to be widely distributed and route around anything that prevents effective communication. By setting itself up as a bottleneck – and an increasingly huge bottleneck as more and more Chinese users get online – the Chinese government is making itself a single point of failure. The slightest error in its configurations will blast traffic in uncertain directions as well as cut off its own users from the internet. For years, experts have been warning about the “balkanization” of the internet, where governments impose greater and greater constraints within their borders and end up effectively breaking up the global internet. What has not been covered in much detail is the downside to the countries themselves if they try to control their users’ requests, yet make mistakes. Source: http://www.theregister.co.uk/2015/01/26/great_firewall_of_china_ddos_bug/